VB.NET学习笔记:使用Random类生成随机数(不重复、数字、字母)
本文共 4983 字,大约阅读时间需要 16 分钟。
VB6.0升级到VB.NET后,发现随机数函数也发生了变化,在VB.NET中Random类是一种能够产生满足某些随机性统计需求的数字序列的伪随机数生成器。
在代码把光标定位到单词Random,点F1键获取帮助。 一、Random类常用知识点(以下内容来源于帮助,): 1、构造函数: (1)、Random() 使用与时间相关的默认种子值,初始化 Random 类的新实例。 (2)、Random(Int32) 使用指定的种子值初始化 Random 类的新实例。 参数为种子值,数据类型为Int32,用来计算伪随机数序列起始值的数字。 如果指定的是负数,则使用其绝对值。 2、方法: (1)、Next:返回一个随机整数。 A、无参数:Next()——返回一个非负随机整数。 B、一个参数:Next(maxValue) ——返回一个小于所指定最大值的非负随机整数。 参数(maxValue):类型为Int32,要生成的随机数的上限(随机数不能取该上限值)。maxValue 必须大于或等于 0。 返回值:类型为Int32,大于或等于零且小于 maxValue 的 32 位有符号整数,即:返回值的范围通常包括零但不包括 maxValue。 但是,如果 maxValue 等于 0,则返回 maxValue。 C、两个参数:Next(minValue,maxValue)——返回在指定范围内的任意整数。 参数(minValue):类型为Int32,返回的随机数的下界(随机数可取该下界值)。 参数(maxValue):类型为Int32,返回的随机数的上界(随机数不能取该上界值)。 maxValue 必须大于或等于 minValue。 返回值:类型为Int32,一个大于等于 minValue 且小于 maxValue 的 32 位带符号整数,即:返回的值范围包括 minValue 但不包括 maxValue。 如果 minValue 等于 maxValue,则返回 minValue。 (2)、NextBytes:用随机数填充指定字节数组的元素。 NextBytes(buffer) 参数(buffer):Byte[],包含随机数的字节数组。 说明:字节数组的每个元素设置为随机数字大于或等于 0,且小于或等于MaxValue。 (3)、NextDouble:返回一个大于或等于 0.0 且小于 1.0 的随机双精度型浮点数。 没有参数,返回值类型为Double。 3、使用方法: 要生成各种类型的随机数,必须先得到它的实例对象,然后再生成随机数。注意只实例化一个对象,可以多次方法调用,生成的数字分布均匀,每个数字返回的可能性均相等。 二、Random类生成随机数的弱点 Random类生成随机数是伪随机数,所以在Random的内部产生机制中还是有一定规律的,并非是真正意义上的完全随机。 如果种子值相同则每次均产生相同的随机数。如下面代码在构造函数中指定了种子值:Private Sub Form1_Load(sender As Object, e As EventArgs) Handles MyBase.Load Dim rand As Random = New Random(66) For i As Integer = 0 To 10 Me.Label1.Text = Me.Label1.Text & rand.Next() & Environment.NewLine Next End Sub
每次运行程序均生成相同的随机数序列,如下图所示,不信你就测试一下。
 三、怎样才能每次运行程序时均生成不同的随机数? 其实很简单,就是每次运行程序时改变Random类的构造函数的种子值,可以有以下做法: 第一种方式: 使用无参数的Random()构造函数; 默认种子值是使用DateTime.Now.Ticks作为种子值的,如果触发Random函数间隔时间很短, 就有可能造成产生一样的随机数。 第二种方式: 使用RNGCryptoServiceProvider生成种子值;生成速度较慢。 在帮助里有看到推荐,如下图:
三、怎样才能每次运行程序时均生成不同的随机数? 其实很简单,就是每次运行程序时改变Random类的构造函数的种子值,可以有以下做法: 第一种方式: 使用无参数的Random()构造函数; 默认种子值是使用DateTime.Now.Ticks作为种子值的,如果触发Random函数间隔时间很短, 就有可能造成产生一样的随机数。 第二种方式: 使用RNGCryptoServiceProvider生成种子值;生成速度较慢。 在帮助里有看到推荐,如下图: 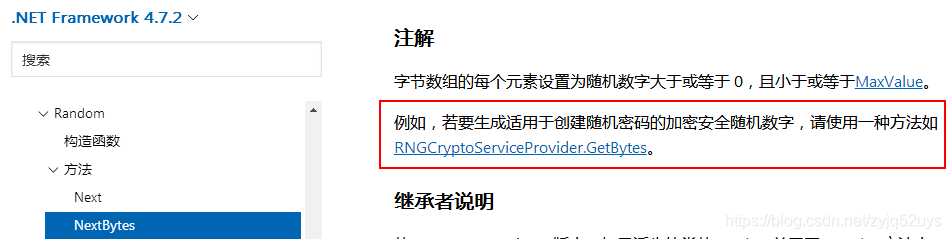 第三种方式: 使用Guid生成种子值; 生成速度快。 测试代码如下:
第三种方式: 使用Guid生成种子值; 生成速度快。 测试代码如下: Public Class Form1 '''''' 通过RNGCryptoServiceProvider获取种子值 ''' '''Private Shared Function GetRandomSeed() As Integer Dim bytes As Byte() = New Byte(3) {} Dim rng As System.Security.Cryptography.RNGCryptoServiceProvider = New System.Security.Cryptography.RNGCryptoServiceProvider() rng.GetBytes(bytes) Return BitConverter.ToInt32(bytes, 0) End Function ''' ''' 通过Guid获取种子值 ''' '''Private Shared Function GetRandomSeedbyGuid() As Integer 'Return New Guid().GetHashCode() Return Guid.NewGuid().GetHashCode() End Function ''' ''' 默认种子值生成随机数 ''' ''' ''' Private Sub BtnTime_Click(sender As Object, e As EventArgs) Handles BtnTime.Click Dim rand As Random = New Random() Me.Label1.Text = "" For i As Integer = 0 To 10 Me.Label1.Text = Me.Label1.Text & rand.Next() & Environment.NewLine Next End Sub '''''' RNGCryptoServiceProvider种子生成随机数 ''' ''' ''' Private Sub BtnRNG_Click(sender As Object, e As EventArgs) Handles BtnRNG.Click Dim rand As Random = New Random(GetRandomSeed()) Me.Label1.Text = "" For i As Integer = 0 To 10 Me.Label1.Text = Me.Label1.Text & rand.Next() & Environment.NewLine Next End Sub '''''' Guid种子生成随机数 ''' ''' ''' Private Sub BtnGuid_Click(sender As Object, e As EventArgs) Handles BtnGuid.Click Dim rand As Random = New Random(GetRandomSeedbyGuid()) Me.Label1.Text = "" For i As Integer = 0 To 10 Me.Label1.Text = Me.Label1.Text & rand.Next() & Environment.NewLine Next End SubEnd Class
四、生成数字和字母组合的随机数
开始想到用ASCII码,但数字、小写字母及大写字母的ASCII码是不连续的,觉得不是很理想,下面的方法感觉还不错,做个笔记。Public Function GetAlphanumeric() As String Dim str As String = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ" Dim rnd As New Random() '返回数字 'Return rnd.[Next](10).ToString() '返回小写字母 Return str.Substring(10 + rnd.[Next](26), 1) '返回大写字母 'Return str.Substring(36 + rnd.[Next](26), 1) '返回大小写字母混合 'Return str.Substring(10 + rnd.[Next](52), 1) '返回小写字母和数字混合 'Return str.Substring(0 + rnd.[Next](36), 1) '返回大写字母和数字混合 'Return str.Substring(0 + rnd.[Next](36), 1).ToUpper() '返回大小写字母和数字混合 'Return str.Substring(0 + rnd.[Next](61), 1) End Function
五、生成不重复随机数
1、 从N个数中随机取出一个数,与数组第N个数调换; 2、 从前N-1个数中随机取出一个数,与第(N-1)个数调换; …… 代码通过_end-1,把生成过的数用最后一个数代替,省去删除移动的开销。 代码如下:Public Function GetRandomSequence(ByVal total As Integer) As Integer() Dim sequence As Integer() = New Integer(total - 1) {} Dim output As Integer() = New Integer(total - 1) {} For i As Integer = 0 To total - 1 sequence(i) = i Next Dim random As Random = New Random() Dim _End As Integer = total - 1 For i As Integer = 0 To total - 1 Dim num As Integer = random.[Next](0, _End + 1) output(i) = sequence(num) sequence(num) = sequence(_End) _End -= 1 Next Return output End Function 本文参考了以下博文:
学习过程得到网友的帮助,表示感谢!转载地址:http://vrjt.baihongyu.com/
你可能感兴趣的文章